
Kotlin Coroutine Pitfalls Record
This article is translated from Chinese to English by ChatGPT. There might be errors.
I’ve been using Kotlin Coroutine in projects for more than a year. Although I’ve only used some very basic features, I still ran into plenty of pitfalls. This post records them as notes.
The runBlocking() deadlock mystery
Look at this piece of code:
val executor = newFixedThreadPoolContext(1, "TEST")
runBlocking(executor) {
runBlocking(executor) { }
}
This code will deadlock. The deadlock is caused by the combination of these two factors:
runBlocking()is not a suspend function, so the innerrunBlockingdoes not yield the thread when executing. Instead, it blocks the thread until the coroutine it created finishes.- When calling
runBlocking()withexecutoras the dispatcher, the coroutine created by the innerrunBlockingwill be put intoexecutor’s task queue waiting to be executed. But the only thread ofexecutoris running the coroutine created by the outerrunBlocking. Due to factor 1, it never gets a chance to execute the queued task, hence the deadlock.
Breaking either of these two factors can avoid the deadlock. Let’s look at factor 2 first. If the inner call is simply runBlocking { }, then there will be no deadlock, because the inner runBlocking will create an eventLoop on the executor’s thread, and then use this eventLoop to run its coroutine.
Now factor 1: if we call other coroutine creation functions in the inner scope, such as async(executor) {}, launch(executor) {}, or scope-creating functions like withContext(executor) {}, coroutineScope {}, since these are non-blocking or suspend functions, they will yield the thread, giving executor the opportunity to execute queue tasks, so no deadlock occurs.
So far the cause of the deadlock is clear. One might think this example is too simple and only useful for teaching; in real usage, you wouldn’t have nested runBlocking() calls, nor a dispatcher with only one thread. However, the pit we hit happened in production.
At that time, once we tried to fetch a list and the requested count was greater than 64, the program froze and could no longer do anything else. And 64 happens to be the default upper thread limit of Dispatcher.IO.
We know that runBlocking() should only be used when bridging between non-suspend and suspend functions. Once we’re in the suspend world, shouldn’t we just keep using suspend functions and naturally avoid nested runBlocking? In practice, when we need to use libraries designed for Java and their APIs accept function parameters, since these libraries are not targeting Kotlin, they naturally do not support suspend functions, so we must use runBlocking() as a bridge. For example, if we want to use Guava’s Cache interface, its get method is like this: V get(K key, Callable<? extends V> loader). The second parameter must be a normal function, not a suspend function. In such cases, the best approach is to find a replacement library. For instance, we replaced Guava’s Cache with cache4k. If no alternative can be found, we should create a dedicated Dispatcher specifically for such runBlocking() calls, for example Dispatchers.IO.limitedParallelism(n).
The coroutineContext scope mystery
Inside any suspend function we can directly access a coroutineContext value, which comes from the compiler extracting the coroutine context from Continuation:
public interface Continuation<in T> {
/**
* The context of the coroutine that corresponds to this continuation.
*/
public val context: CoroutineContext
...
}
However, the CoroutineScope interface also has a property with the same name coroutineContext:
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
When both values appear in the same scope, the coroutineContext provided by CoroutineScope takes precedence. So the following code prints a instead of b:
suspend fun runInNewContext(block: suspend () -> Unit) {
withContext(CoroutineName("b")) {
block()
}
}
fun main() {
runBlocking(CoroutineName("a")) {
runInNewContext {
println(coroutineContext[CoroutineName]?.name)
}
}
}
Here, coroutineContext refers to the one provided by the CoroutineScope that is the receiver of runBlocking’s parameter block: suspend CoroutineScope.() -> T.
To make the code above print b, just replace coroutineContext with currentCoroutineContext().
This is a minor issue, but the first time I encountered it, it was quite confusing.
The Exception swapping mystery
Consider this unit test code:
@Test
fun test() {
val expected = Exception("test")
val actual = assertThrows<Exception> {
runBlocking {
coroutineScope {
throw expected
}
}
}
assertEquals(expected, actual)
}
We run the tests with Gradle + JUnit 5. Intuitively this code should pass without any problem. In reality, the test fails, expected != actual, and expected becomes the cause of actual, i.e., actual.cause == expected.
This is very puzzling. Later, by setting a breakpoint in the constructor of a custom Exception, we found it was instantiated twice. The second instantiation was due to a call to recoverStackTrace(), which led us to Stacktrace recovery.
This should be a mechanism to aid debugging, but I didn’t really see much difference from the examples, so I’ll leave the details for later.
The documentation also explains how to disable this mechanism. For our Gradle + JUnit-based tests, we need to put the required JVM parameter into build.gradle.kts:
tasks.test {
useJUnitPlatform()
allJvmArgs = listOf(
"-Dkotlinx.coroutines.stacktrace.recovery=false",
)
}
The ResultSet closing mystery
Our project uses Exposed, JetBrains’ official ORM framework for Kotlin. However, JDBC is inherently incompatible with coroutines because it only provides blocking APIs. Exposed more or less forces out a set of functions to adapt to coroutines and suspend functions, including newSuspendedTransaction() suspendedTransaction() suspendedTransactionAsync().
When we unintentionally used async() inside a suspended transaction and performed database operations there, we intermittently encountered the following issue:
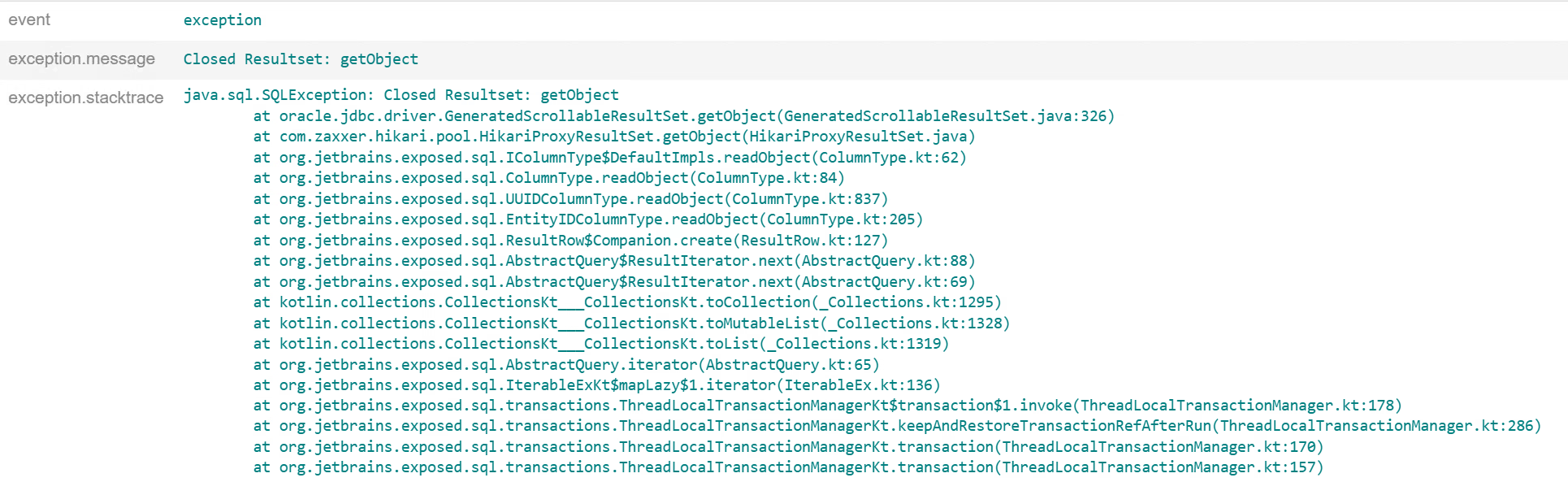
The deeper cause is still unclear. The workaround is to use suspendedTransactionAsync() instead of async() for database operations, or simply avoid asynchrony and perform database operations sequentially.
The problem with suspendedTransactionAsync() is that it always creates a new transaction (according to JDBC principles, it should be acquiring a new connection), which may lead to potential data inconsistency with the original transaction. In short, it’s not ideal, but there’s no better option for now.