
Kotlin Coroutine踩坑记录
在项目中应用Kotlin Coroutine一年多了,虽然用到的都是一些非常基本的功能,但是也踩了不少坑,本文将这些坑记录下来做个笔记。
runBlocking()死锁之谜
看这样一段代码:
val executor = newFixedThreadPoolContext(1, "TEST")
runBlocking(executor) {
runBlocking(executor) { }
}
这段代码会产生死锁。造成死锁的原因是以下两个因素叠加:
runBlocking()不是一个suspend函数,因此里层的runBlocking在执行时并不会让出线程,而是阻塞线程直到它创建的coroutine执行完毕- 调用
runBlocking()时指定了executor为调度器,那么就会把里层runBlocking所生成的coroutine作为task放入executor的队列里等待执行。而executor的唯一线程正在执行外层runBlocking生成的coroutine,由于因素1的关系,它根本没有机会去执行队列里的任务,从而造成死锁
打破以上两个因素的任意一个都可以避免死锁。我们先来看因素2。如果在调用里层runBlocking的时候直接写runBlocking { },那么就不会死锁,
因为里层runBlocking会在executor的那个线程上创建一个eventLoop,然后用这个eventLoop去执行它生成的coroutine。
再来看因素1,如果在里层调用其它的coroutine创建函数,例如async(executor) {},launch(executor) {},或者是创建scope coroutine的函数,如withContext(executor) {},
coroutineScope {},因为这些都是非阻塞或是suspend函数,它们会让出线程,使得executor有机会去执行队列里的任务,因此也不会死锁。
那么到这里关于死锁的原因已经解释清楚了。读者可能会认为这个例子非常简单,最多用于教学,在实际使用中不会遇到runBlocking()嵌套的情况,也不会遇到调度器只有一个线程的情况。然而我们踩的坑就是在生产环境中遇到的。
当时的情况是,一旦我们尝试去获取一个列表,并且请求的数量大于64的时候,程序就会卡死,再也做不了其它任何事情。而64正好是Dispatcher.IO的默认线程上限。
我们知道runBlocking()应该只在需要桥接非suspend函数和suspend函数时才使用,那么一旦进入了suspend的领域,之后一直用suspend函数不就好了吗,就不会导致runBlocking嵌套了。实际情况是,
当需要用到一些针对Java开发的包,并且它提供的接口需要函数输入的时候,由于包本身就不是针对的Kotlin开发的,自然不支持suspend函数,就必须使用runBlocking()进行桥接。比如我们想用Guava的Cache接口,它提供的
get的接口是这样的:V get(K key, Callable<? extends V> loader),这第二个参数就必须提供一个普通的函数,不能是suspend函数。遇到这种情况,最好的办法还是寻找替代品,例如我们用了cache4k替代了Guava的Cache。
如果实在找不到可以替代的包,那么应该生成一个独立的Dispatcher,专门给这里的runBlocking()使用,例如Dispatchers.IO.limitedParallelism(n)。
coroutineContext作用域之谜
在任何suspend函数里我们都能直接访问一个coroutineContext的值,它来自于编译器提供的从Continuation中提取的coroutine context:
public interface Continuation<in T> {
/**
* The context of the coroutine that corresponds to this continuation.
*/
public val context: CoroutineContext
...
}
然而在CoroutineScope接口里也有一个同样名为coroutineContext的属性:
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
当这两个值同时出现在一个作用域里时,CoroutineScope接口提供的coroutineContext胜出。所以以下代码会打印a而不是b
suspend fun runInNewContext(block: suspend () -> Unit) {
withContext(CoroutineName("b")) {
block()
}
}
fun main() {
runBlocking(CoroutineName("a")) {
runInNewContext {
println(coroutineContext[CoroutineName]?.name)
}
}
}
这里coroutineContext访问的是runBlocking参数中block: suspend CoroutineScope.() -> T,作为receiver的CoroutineScope提供的coroutineContext。
要想让上面的代码打印出b,将coroutineContext替换成currentCoroutineContext()即可。
这只是一个小问题,只是头一次遇到的时候搞不清楚还是挺让人懵逼的。
Exception调包之谜
来看一段单元测试代码:
@Test
fun test() {
val expected = Exception("test")
val actual = assertThrows<Exception> {
runBlocking {
coroutineScope {
throw expected
}
}
}
assertEquals(expected, actual)
}
我们使用Gradle + JUnit 5运行的单元测试,从直觉上看这段代码应该通过测试,没有问题才对。实际情况是测试失败,expected != actual,并且epected变成了actual的cause,也即actual.cause == expected。
这非常让人疑惑。后来通过在自定义的Exception构造函数里打断点,发现确实被实例化了两次,第二次实例化是因为调用了一个recoverStackTrace()的函数,于是顺藤摸瓜找到了Stacktrace recovery。
这应该是一个方便调试的机制,但是我并没有从例子里看出有什么大区别,先不求甚解以后再说了。
文档里也写了如何关闭这一机制,对于我们上面用Gradle写的单元测试而言,需要将所需的JVM参数写在build.gradle.kts里:
tasks.test {
useJUnitPlatform()
allJvmArgs = listOf(
"-Dkotlinx.coroutines.stacktrace.recovery=false",
)
}
ResultSet关闭之谜
我们的项目使用Jetbrains官方为Kotlin开发的ORM框架Exposed。然而JDBC天生和coroutine不搭,因为JDBC提供的都是阻塞API。Exposed可以说是强行提供了一套函数以适配coroutine和suspend函数,
包括newSuspendedTransaction() suspendedTransaction() suspendedTransactionAsync()。
当我们无意中在suspended transaction里使用了async()并在其中进行了数据库操作之后,就有概率遇到以下问题:
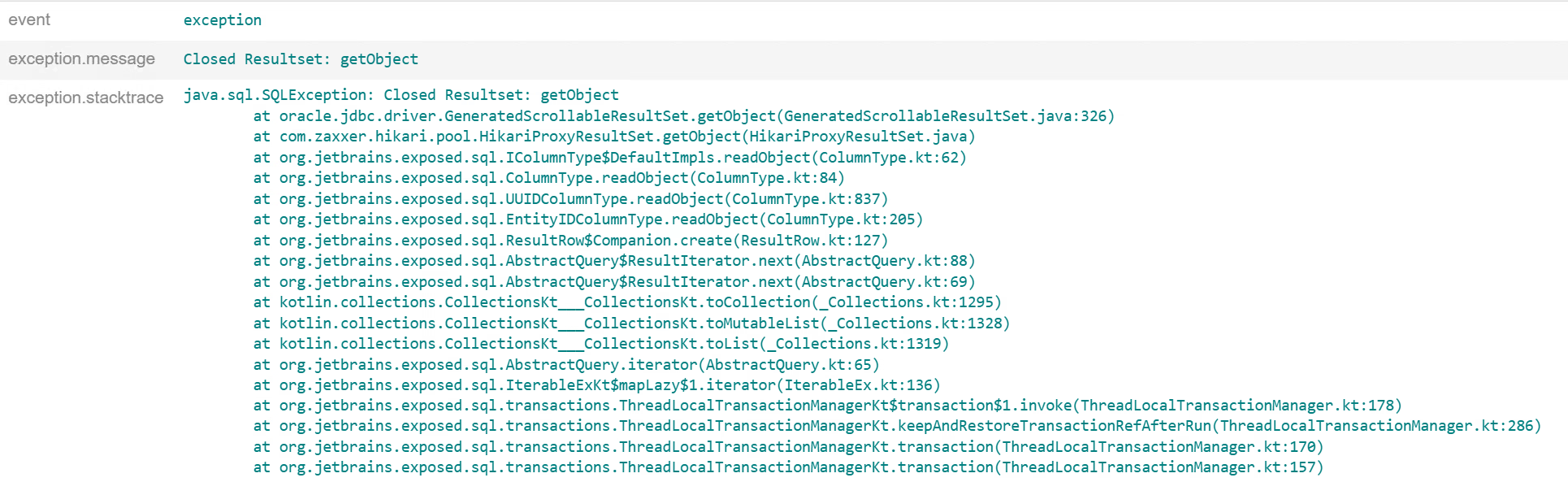
目前尚不清楚深层次的原因。解决方案是使用suspendedTransactionAsync()代替async()进行数据库操作,或干脆不使用异步,按序执行数据库操作。
使用suspendedTransactionAsync()的问题在于无论如何它都会新建一个transaction(根据JDBC的原理,应该就是新拿了一条connection),这样会有潜在的与原有transaction数据不一致的问题,
总之就是不够完美。但是也别无他法了。